In a movie/series/commercial context, a day on set may cost tens of thousands of dollars and can produce
terabytes of data. (IOW, the data is extremely valuable.) The data must be offloaded from camera's magazine to external
disks reliably and fast because magazines are reused quickly. ("Magazine drives"
must support recording of RAW high-resolution data in real-time. Because of this, their cost is way higher than
that of an average SSD drive , so there are only a few on the set, like two per camera). The data is also insured, and the insurance company
requires that there be at least two copies of the data, with the file hash being stored in some kind of a side-car catalog.
In "manual workflow", MHL is used for this purpose, but we stored all metadata in the asset database.
Quine.FileTransfer helps with a superficially simple problem: copying a file from source to one or more destinations.
("Source" and "destination" are abstract terms for the library: they may be a local disk, SMB mount or even BLOB storage in the cloud.)
As the subsequent sections will explain, the problem is far from superficial when speed and data integrity
are key features. An earlier version of this library was the work-horse of QuineIngest and was used to copy many terabytes of data
in real productions. This version of the library is released with a cleaned-up API, more extensive test
suite and a quick-start application.
A file is copied to multiple destinations in at most two passes.
With proper configuration, it is possible to read/write data at nearly maximum throughput.
Obviously, the total transfer time is limited by the slowest source / destination.
The integrity of the transfer can be optionally verified after copying by a 2nd hashing pass. Each worker performs hashing
in parallel with other workers, and the hashing algorithm can be chosen by the user.
It allows opening of a file without OS buffering to ensure that hashing verifies the
content actually present on storage instead of its in-memory copy.
Allows cancellation of transfers.
Errors occuring during copying to one or more destination must not affect copying to other destinations.
Errors are reported reliably. If an error occurred either at source or destination(s), it will be reported
through the worker's exception property.
Extensibility: Out-of-the box, the library supports only OS files as source and destination. However,
it is possible to support other types of sources and destinations (e.g., FTP, Azure BLOBs or even DropBox)
without meddling with the core logic. By applying decorator pattern, it is possible to
add features such as retry, timeouts and progress reporting. This allows for clean separation between
concerns and layered approach to system development.
Support for sources and destinations that can read/write multiple file blocks in parallel.
The library comes with a stress-test program.
Note
The library is delivered with a number of low-overhead Trace.Assert statements that ensure basic invariants
which, if violated, would in the worst case lead to silent data corruption. It is therefore not recommended to recompile the library
without the TRACE macro defined.
The assert behavior depends on the trace listeners collection. The collection should be configured such that the program is
stopped on assertion failure (which is the case by default).
Concepts
This library is used to copy a single file from an abstract "source" to one or more abstract "destinations".
Sources and destinations are "abstract" in the sense that their backing storage can be OS files, FTP servers, Azure BLOBs, etc.
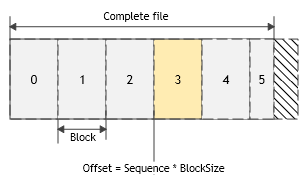
A file is an ordered sequence of bytes partitioned into equally-sized blocks.
The file's size will almost never be a multiple of the block size: the example diagram shows a file consisting of 6 blocks:
5 whole blocks (numbered 0-4) and one partial block (numbered 5; the striped portion is unused buffer space).
The block size is determined upon the
creation of TransferDriver and
cannot be changed. It is available through BlockSize
property.
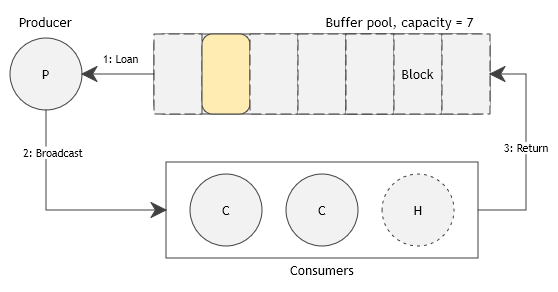
Producer/consumer view of a file
The copying process involves the following (active) participants
Driver
Users of the library use an instance of TransferDriver
to start or cancel a file transfer and control hash verification. Internally, it serves as a "blackboard" for coordination between
the producer and the consumers. Among other things, it holds a preallocated pool of buffers (equally-sized blocks of native memory)
which are freed when the driver instance is disposed.
Buffer (block)
A block of memory managed by the driver and used to transfer file data from the producer to the consumers. An individual
buffer is represented by ITransferBuffer
instance. (Other properties, such as use count, are present as well, but are internal to the
assembly.) The buffer's position in the file is determined by Sequence
property.
Producer
A class implementing ITransferProducer
that fills a memory block with data obtained from a source. (Example: reading from an OS file.)
Consumer
A class implementing ITransferConsumer
that processes data handed over by the producer. (Example: writing to an OS file, or adding data to incremental hash computation.)
Data flow in a file transfer
For each transfer, the producer and consumers execute the following algorithm:
Initialize (e.g, open an OS file).
Loop until EOF or exception.
The producer obtains a buffer from the pool and fills it with data.
If there is no more data at the source, it signals EOF to the consumers.
Otherwise, it broadcasts the buffer to the consumers and keeps reading the data.
The consumer waits for a buffer from the producer and process it (e.g., hash it or write to backing storage).
After processing, it returns the buffer to the buffer pool.
Reference counting ensures that the producer cannot reuse a buffer before it has been returned by all consumers.
Compute verification hash (if requested) and finalize (e.g., close an OS file).
Depending on how the concrete implementation defines MaxConcurrency,
the loop in step 2 might spawn many parallel tasks. Errors are handled by the framework: if the producer or any consumer has failed,
its Exception property will
reflect the failure. If all consumers fail, the driver cancels the rest of the transfer.
Extending the library
Out of the box, the library supports only unbuffered native files on Windows and OSX as producers and consumers; these are derived from
UnbufferedFile.
As the name suggests, it turns off OS buffering to make sure that the data being read or written actually comes directly from
the backing media instead of from the OS cache. (Turning off buffering was necessary because QI handled valuable data. In situations
where a magazine would completely fit into the machine's cache, the point of hash verification would be completely defeated
as it would read the data back from the cache instead of from media. Unbuffered IO -- when
done right -- is also more performant because it avoids double copying of data, first to the OS cache in kernel-space, followed
by copying from cache to user-space buffer.)
Tip
Use existing implementations as guidelines.
To add new behavior to existing implementataion of producer or consumer, use the decorator pattern with composition.
If the interface methods are implemented virtually, it is also possible to use subclassing with base invocation: this
approach is not composable, but it entails less boiler-plate when a reusable decorator is not needed.
To support other hash algorithms, create a class implementing ITransferHasher.
To add support for storage mechanisms other than local files, create classes that respectively implement
ITransferProducer
or ITransferConsumer.
Design the implementation so that the same instance is reusable for many transfers.
DO check for cancellation manually if the I/O methods do not natively support cancellation. The cancellation token is available
through CancellationToken
property on State.
If the implementation has MaxConcurrency
equal to 1, it is guaranteed that sequence numbers referring to file blocks to be processed will be sequential. This makes
it possible to support non-seekable sources/destinations (e.g., tape drives).
Use exceptions to signal errors. If you study existing producers and consumers, you will see that they do not catch
exceptions: try/finally blocks are used for resource management. The framework will stop
invoking FillAsync
or DrainAsync
after an exception has been thrown, regardless of concurrency level.
InitializeAsync
and FinalizeAsync
manage lifecycle of an individual transfer and they are therefore always invoked. Use the initialize method to acquire "resources"
and finalize method to release them. If errors occurred during execution, the hasher argument to FinalizeAsync
is guaranteed be null.
Important
For correct operation, it is crucial that FillAsync and DrainAsync
fill/drain the complete buffer Memory.
The ONLY case where it's allowed that Data
is shorter than Memory is
the last block of the file as shown in this figure.
FinalizeAsync is invoked even if InitializeAsync threw. Ensure that
this case is handled correctly.
FillAsync and DrainAsync MUST NOT "steal" a reference to ITransferBuffer,
or any of its members, for later use.
The rationale behind the "weird" signature and sematics of
FinalizeAsync
is that it must be possible to compute the verification hash before releasing the resources associated with the file being read/written.
War story: an older design with different signature of FinalizeAsync closed the file after writing and reopened
it for hashing. In production use, this caused hash verification to spuriously fail with "file in use" exception. The investigation
revealed that the small time-window between closing and reopening the file was enough for an anti-virus program to kick in and open
the file in "no share" mode.