When we started with QI, we knew it had to be modular and that workflows must be data instead of code
as was the case with Gamp (see "History" below). I earned my PhD researching Kahn process networks and that pushed me towards a graph-based approach
where nodes process data and edges define data-flow. We agreed that it was the right approach, not the least because it would
be familiar to at least some of our users as, e.g., Foundry's Nuke uses it.
Before embarking on making this framework, I studied the TPL Dataflow library in some detail, and it left me in doubt about
whether it could be adapted to all of our upfront requirements:
Workflow description must be serializable independently of the code that executes it.
Messages present in the edges must also be serialized / deserialized. (The intention was to be able to cancel workflow
execution and resume it at a later point. We solved this in another way though and removed this capability from the code.)
Event reporting and interactive queries. The latter sends an event to the front-end and blocks the
node until a reply is received.
Persistent (serializable) trace of graph execution.
As will become evident from the "Getting started" section, the graph topology
is decoupled from the code executing it. This enabled users to create libraries of "workflows templates". The user could load
a workflow template from the database, customize parameters (e.g., input path with files to process) and then start the job.
Historical note
Quine was a follow-up to another failed startup where we (the co-founders) first met. In that previous startup, we developed
a workflow application called Gamp. It was loved by users, but it had severe technical
problems: workflow steps were hard-coded
into the application and were inter-twined. Any customization pretty much needed also a few debugging sessions to get it right.
Not the least, it was coded in Qt and C++, which was a nightmare to deploy on two different platforms. (Windows ans OSX,
OSX being the worst.)
"Gamp" is a norwegian word for a work-horse.
QI had a number of predefined node types that performed various "fixed" functions whereas users were able to create flexible
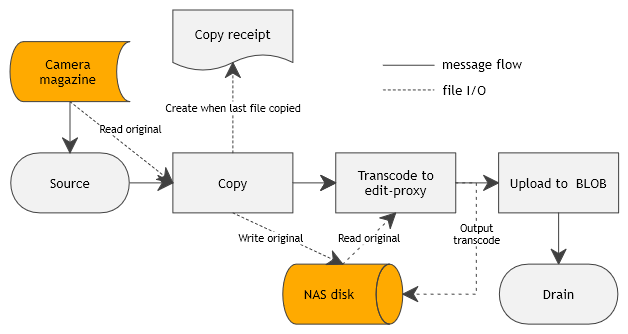
workflows on their own; an example is shown in the figure below.
Simple Workflow
While QI was a huge technical advancement over Gamp (hey, no need to compile and deploy a new binary in order
to support a slightly different workflow!), the figure hints at messiness of the real-world that did not fit neatly into the graph framework
and which we implemented through various ad-hoc "hacks":
Users wanted an estimate of global progress ("when will the job finish?"), not just progress of individual nodes
for individual files. While parallel execution of nodes extracts performance (e.g.: while file #13 is being copied,
file #4 is being transcoded and file #3 is being uploaded), it is difficult to show to the user what's going on.
Copy node is special. Users want to immediately know when all files have been copied and verified so that they can
reuse the original magazine ASAP.
In a "clean" implementation, nodes should not need to know about each other. However, situations occurred
where they had to inspect parts of each other's state.
Semi-success states. Processing a file at a node might result in an error, but this should not mark the whole job
as being in error state.
Tip
The real world is messy.
Users want automation, but they also want to "feel in control". They are, in fact, NOT in control when the automation overtakes
manual tasks, but the illusory perception of control is important from the UI/UX perspective.
Even though QI was a powerful and performant tool that was used on at least 150 professional drama productions over the
years, the users were
never "happy"; they "tolerated" it because it saved them many hours of work per day. One big reason was its
data-oriented UI, which required a "workflow expert" to configure it before use in a production.
Another big reason were its lacking reporting capabilities that would provide them with the illusion of control.
We were simply unable to find a satisfactory UI/UX solution to users' conflicting requirements:
Users want performance and automation with little interaction: this is best achieved with batched, asynchronous and parallel execution.
Users want the same kind of intuitive feedback about job state that they're used to getting from interactive, serial processes.
Our users got their job done, many work hours were saved (less overtime!), but they were never confident in QI having
performed all the tasks it should. This distrust persisted even after many successful workflow runs because they never felt that
they were "in control".
Concepts
The basic concepts are nodes which are connected through ports which are used
to exchange messages. A connected set of nodes constitutes a graph. Message receiving is handled
implicitly by the base classes, while messages must be sent explicitly to an output port.
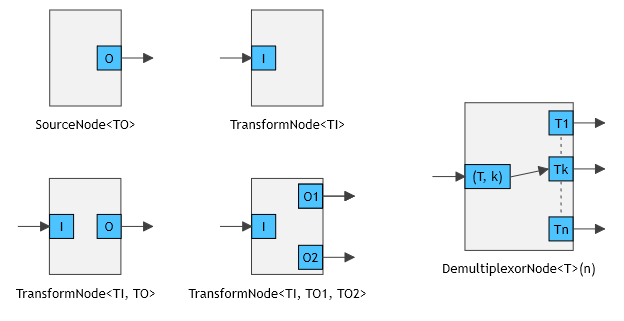
Predefined abstract node types
A node can have at most one input port for
receiving messages, and 0 or more output ports for sending messages. Predefined (abstract) node types are shown in the
figure below. A node with multiple input ports is not provided because 1) they weren't needed to define real-world
workflows, and 2) it provides multiple, equally-valid, implementation options. ("AND": node fires when there's a
message on every port, "OR": node fires when at least one port has a message.)
Every graph must have a single source node and a single drain node (a transform
node with no outputs). The latter requirement is somewhat artificial but aids in validation before the graph is
started:
Every output port of every node must be connected to at least one input port.
It is allowed to connect the same output port to many (different) input ports
Every input port of every node must have a connection from at leat one output port.
These checks exist to ensure graph termination when there are no more messages to process.